資料處理就像是一個自來水處理系統,你有上游水的來源,有要輸送到終點的家家戶戶、工廠,中間有許多大大小小的資料轉換、要整合哪些不同資料源、要決定怎麼計算,以及存到哪個地方,ETL 與 ELT 的選擇是決定轉換和載入的大方向,接著就要進到更細節的思考問題:決定水要怎麼流?
Apache Airflow 是一個幫助你達成 data orchestration 的data pipeline 管理工具,透過 Airflow,資料團隊就能針對整個資料工作流做排程、監控、管理,對於管理有複雜相依性的資料處理是個強大的助手,能讓團隊更清晰、更高效率的從數據得到有價值的洞察。
這邊我會簡單帶過幾個我覺得比較重要的概念,讓沒接觸過的讀者還是能初步了解,網路上有很多針對 Airflow 使用很詳細的教學。
Airflow 能透過 DAG file 很容易的設置好你要排程跑的資料處理腳本,並且在 Web interface 做到視覺化資料流的管理。
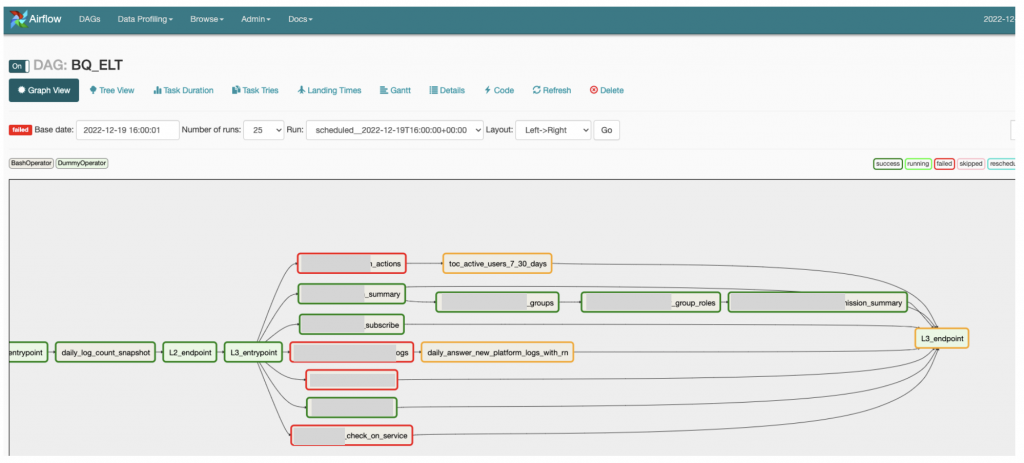
Directed Acyclic Graph(有向無環圖),就是有順序性、沒有loop 的工作相依關係,DAG 就是用來管理一個 dataflow 裡面多個資料處理小任務的依賴關係,如上圖所示,在實務上的資料流有很多先後處理的順序性,就能透過 DAG definition file 做到很簡潔的管理。
Scheduler 幫忙將要執行的項目送到 Executor;Executor 負責工作任務的啟動調度;Worker 負責執行任務;Operators 能幫助你呼叫各種程式語言的資料處理腳本,例如 PythonOperator 可以讓你從airflow 呼叫 python的資料處理腳本,更詳細架構可以參考官方文件的說明,這裡就不贅述。
在一開始導入 ELT 流程,我們的技術選型是:
實作的方式是透過 Airflow 來幫助我做資料處理的複雜相異性,airflow 會去呼叫 python & R的腳本,這些腳本會 call GCP API,到BigQuery中執行SQL做資料表的計算轉換。透過這個很簡易 serverless 的ELT Pipeline 先做成效的驗證。
實務上很常見的一個問題是資料沒有正常跑,上游壞了下游壞光光,要重跑好困擾,可能會把好的資料又蓋掉?我想分享兩個重要的概念: idempotency 以及 Backfill
backfill 是 Airflow 裡面提供的機制,在任務執行失敗以後,能自動重新執行任務,也有提供手動指令讓你重跑。
在一開始設計資料流的時候,經驗還不太夠,最常發生是前一天資料有某些原因沒有跑,或是有順利執行,但是某個資料的產生規則改變了,導致我的計算有一段時間要重跑,在你的資料腳本設計不好的時候,重跑或是需要先刪除錯誤資料,就會是一個很大的困擾。
中文是『等冪性』,代表的含義是當你執行一個改變的行為時,執行多次都會得到相同的結果。
這個概念在每天日常資料流設計,以及在 backfiil 時很重要,先用程式舉個簡單的例子:
function addition(num1, num2){
return num1+num2;
}
addition(3, 4); //output is 7
let array = [3,5,7,11,13];
function removeLastItem(process) {
process.pop();
return process;
}
removeLastItem(array); // array = [3,5,7,11]
removeLastItem(array); // array = [3,5,7]
以上述的例子來說 addition 屬於 idempotence,因為每一次的input 只要一樣,輸出就會一樣;而 removeLastItem 就不符合 idempotence的規則,每一次把array 丟進去都會得到不同的結果。
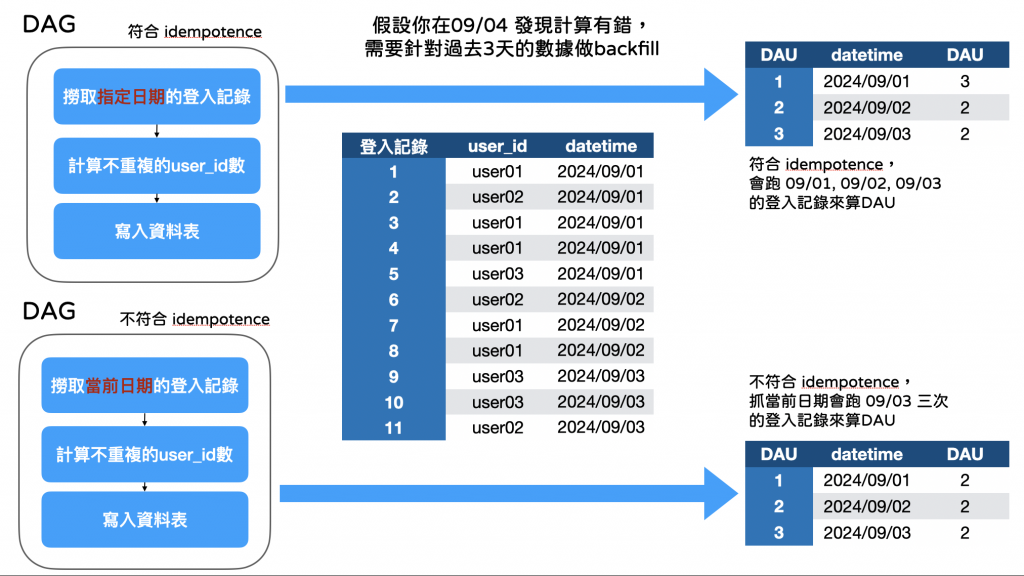
這個概念用在資料流的設計是確保你的資料從源頭、計算到結果更容易被管理,在產品分析經常需要計算每日活躍用戶人數(DAU),在一開始建立資料轉換時,犯過一個錯,就是日期抓取是動態抓取當前日期,下圖有兩個計算案例:
第一種算法符合 idempotence ,第二種不符合,當你需要跑backfill 的時候,第二種算法就會導致你要跑過去的資料,卻都抓到當下日期做為參數,導致資料被錯誤計算,在資料品質的管理和修正就會非常麻煩。
Airflow 是一個做data orchestration 的data pipeline 有效管理工具,如果想更深入使用,可以參考官方文件,網路上也有更深入的教學,所以今天的文章也額外分享過去在資料轉換失敗,要重跑資料時的慘痛經驗,與你的資料表設計、資料流進來要怎麼放有很重要的關聯。
聊到資料表的設計,明天我們就來聊聊 OLAP 的資料表要怎麼設計。


 iThome鐵人賽
iThome鐵人賽